
In the last blog post I achieved to have a working TTS with text-generation-webui, The IA is speaking to me in a "almost" natural way, there was some delay due to the time to generate the wav file and send it to my browser. You can read all about it here :

Now I wanted to go a further and try to make the process go faster, so I read a lot of posts on the TTS topic, I found very useful informations and a lot of field experience feedbacks from the community.
I came across AllTalk TTS extension for text-generation-webui here is the result :
To install this extension assuming you followed the installation in the previous blog post
# going into the text-generation-webui directory
cd /opt/text-generation-webui/extensions
# cloning the repo
git clone https://github.com/erew123/alltalk_tts
# entering the virtual environment
bash ../cmd_linux.sh
# installing requirement
pip install -r extensions/alltalk_tts/requirements_nvidia.txt #if you have a nvidia GPU requirements_other.txt if you do not
cd ..
# starting text-generation-webui
bash start_linux.sh --listenTo enable this extension, on the text-generation-webui go to the session menu on the top and check the box AllTalk_tts then click on Save UI default to settings.yaml

during the initial launch models are being downloaded, allow it some times
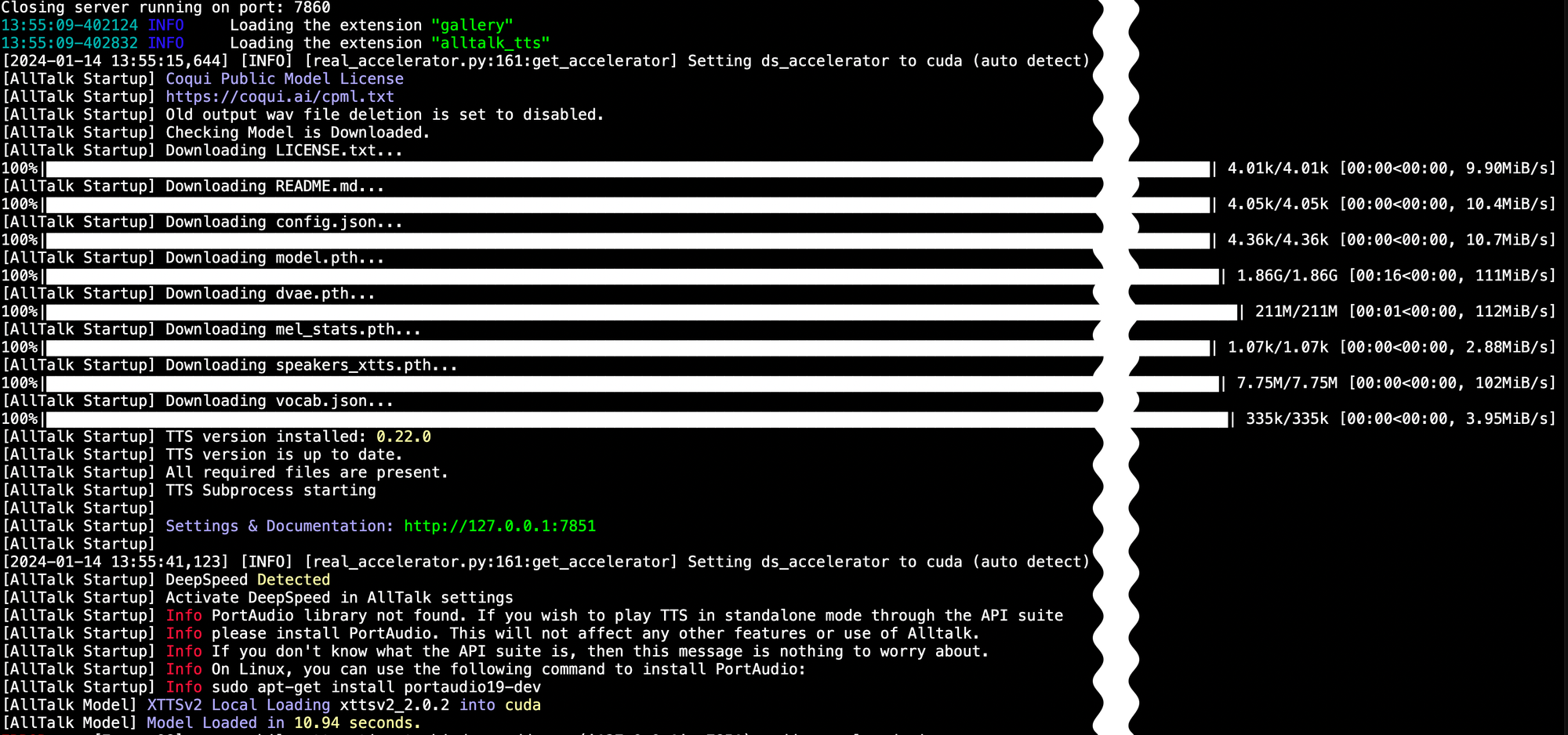
It should be good to go now, let's try it :
There is an add-on for this extension deepspeed which can be installed to optimise the performance of the rendering.
To do so, you need to install the CUDA Toolkit Archive here https://developer.nvidia.com/cuda-toolkit-archive
Download the latest CUDA Toolkit, answer the question and install as explained.
then run these lines :
# going into the text-generation-webui directory
cd /opt/text-generation-webui
# run this script to enter the virtual environement
bash cmd_linux.sh
# Change the environement variable for CUDA_HOME
conda env config vars set CUDA_HOME=/etc/alternatives/cuda
# Check if it's saved
export CUDA_HOME=/etc/alternatives/cuda
exit
# Install Deepspeed
bash cmd_linux.sh
pip install deepspeed
exit
# launch the text-generation-webui script
bash start_linux.sh --listenNow to enable deepspeed, navigate to the chat section on the bottom in the TTS menu and just check the box to enable it, wait for the sound activation to play : deepspeed enabled
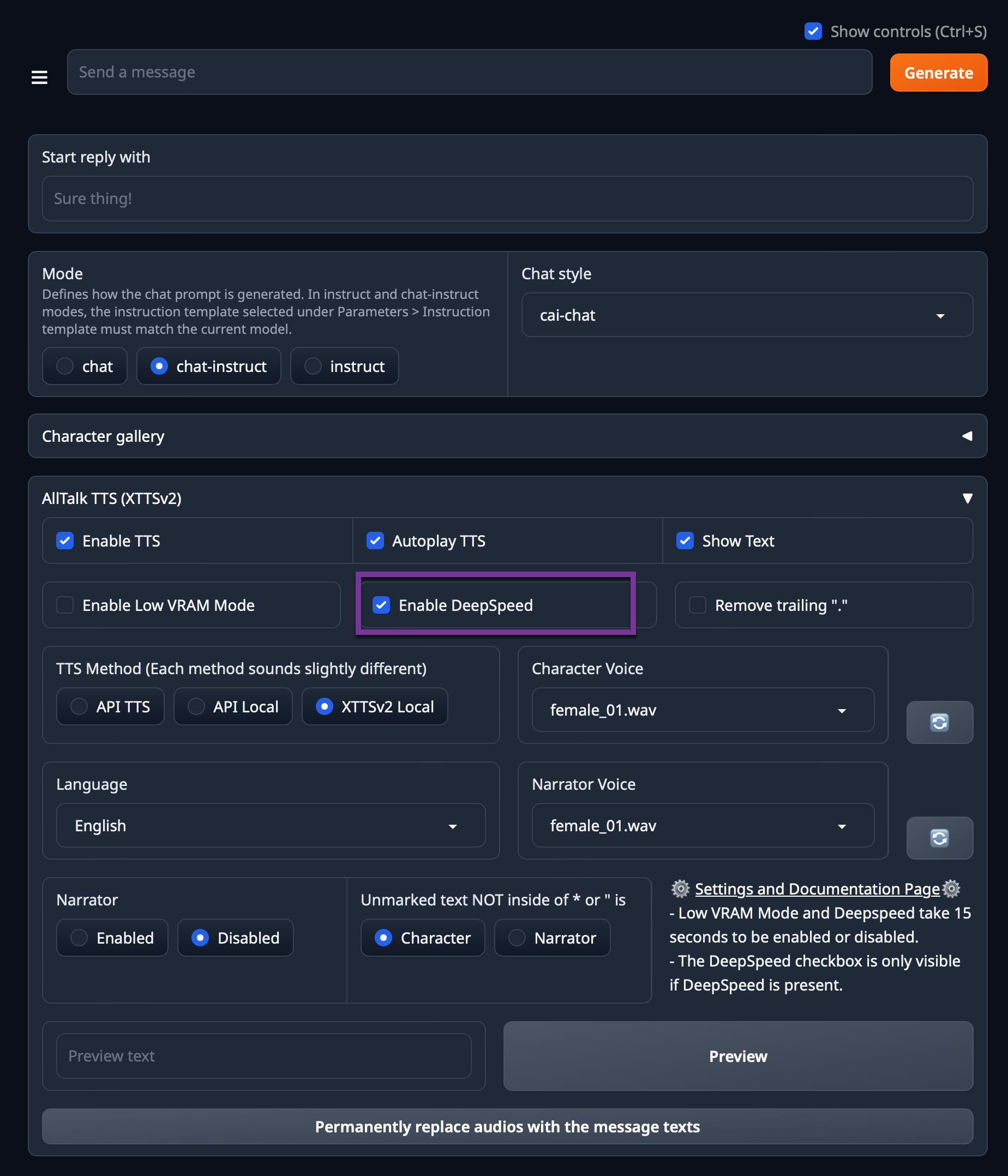
The example I posted earlier in this article call for longer answer, it stil take some times and if you don't have enough vram available can lead to crash the wav generation.
The time it takes to have the answer by text is almost instantaneous, but the time to generate and encore the wav file takes some times. I think it also depend of the model and the perplexity of the request. In the video I asked two things the model I use hasn't been trained for, music and crypto money.
Anyway this is very mind blowing the natural way this IA is speaking, it's very fluent and nice to listen to.
The next step is to share how I build the Samantha character and share with you the files I have generated to you can try on your side to mess around with it.
 erew123
erew123