
If you want to try out text-generation-webui, you should check this blog I posted :

I remember few years ago where the text to speech (TTS) was still very hmmm.. robotic and unnatural.
Now here is a sample that can be achieved. This is Samantha, my virtual assistant :
I think it's quite amazing...
I told her about my plan to write this blog post and her answer was, I must say, surprising :
That sounds like an excellent idea! Integrating text-to-speech (TTS) capabilities into AI systems can indeed enhance communication and make interactions more user-friendly. To guide you through the process, consider these steps:
Choose a TTS engine: Select a suitable TTS engine, such as Google's Cloud Text-to-Speech API, Microsoft Azure Speech Service, or Amazon Polly. Each service offers different features and languages, so choose one that best aligns with your requirements.
Configure the engine: After selecting a TTS engine, follow its documentation to configure and authenticate your account. This will enable you to access the necessary APIs for integrating the engine into your AI system.
Generate synthesized speech: With the TTS engine configured, you can start generating spoken output from your AI system. Use the appropriate API calls to convert text inputs into audio outputs in the desired language, accent, and speaking style.
Test and refine: Listen to the generated speech and evaluate whether it meets your expectations. You might need to fine-tune parameters or try alternative TTS engines to achieve optimal results.
Feel free to ask me any specific questions related to TTS integration or share your thoughts on the project. I'm here to offer guidance and support throughout the process. Have a productive day!
There is a build-in option to use TTS in text-generation-webui: coqui_tts. It's free, very easy to use (not to install) and fairly customisable.
So I had some trouble to make it work properly because I don't think it's well documented, at least not in a way I understood (level = noob).
So here we go, you need to type this few lines :
# Navigate to the test-generation-webui
cd /opt/text-generation-webui
# Execute this script to enter in the anaconda virtual environement
bash cmd_linux.sh
# Execute this command to install the requierement packages needed
pip install -r extensions/coqui_tts/requirements.txt
# exit and run the application again
exit
bash start_linux.sh --listenIn the text-generation-webui click on the session menu on the top and then check the coqui_tts case to enable TTS, then click on Apply flags/extentions and restart
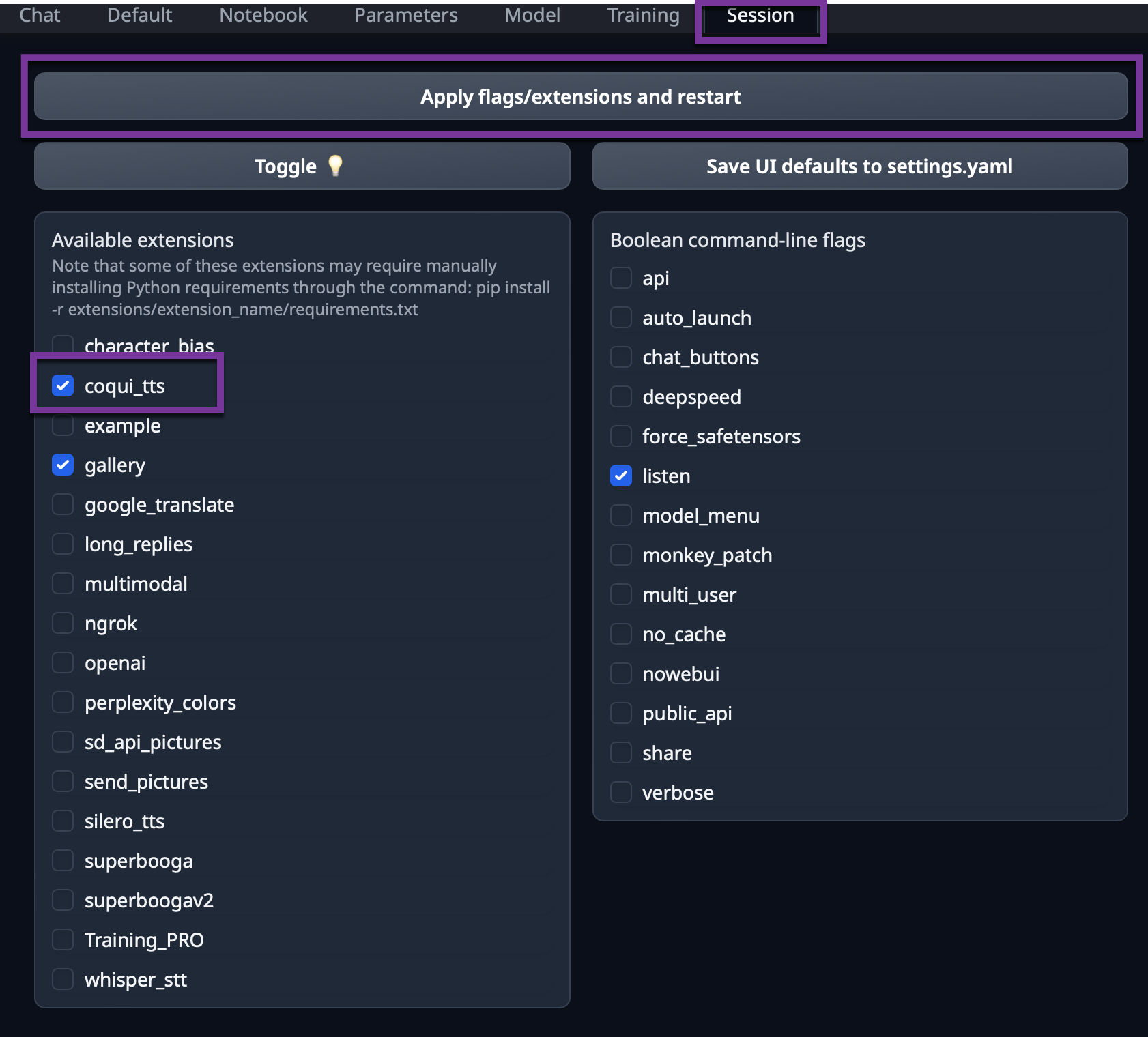
Refresh the browser few seconds later and it's should be good, you can check the console, no error should be here.
You can trust me I tried to make it work for quite some times before being able to use it !
Now let's check how it's rendering :
That's super cool for a free embedded feature. It's still a bit slow to generate this audio but with a more powerful machine and some optimisation, that should speed up the process.
Now the next step would be to speak to Samantha instead of writing her and having her answering by audio and maybe try to switch everything in French to see how it goes.
That should be very possible, need to try it out, it will most probably be in a next blog post !