
Language processing has come a long way, thanks to the rise of large language models (LLMs). However, leveraging these advanced technologies often requires significant computational resources or reliance on cloud services. Enter OLLAMA - the Open Language Learning Architecture that breaks down these barriers and empowers developers to create powerful natural language processing applications right from their local machines! Read on to learn more about this revolutionary platform and how it can revolutionize your approach to language modeling.
Link to Ollama :

I have few Nvidia GPUs to use for that and I will configure Ollama to use 2 GPUs, first if you haven't do it already, let's install Docker on a Ubuntu 22.04.03 server
curl https://get.docker.com/ > docker.sh
chmod +x docker.sh
sudo ./docker.sh
sudo usermod -aG docker $USERRestart the VM / Computer here
Then we need to clone the git repo of Ollama web UI:
cd ollama-webui
chmod +x run-compose.sh
./run-compose.shThat's simple as that, you're good to go and create the admin account using the url
http://xxx.xxx.xxx.xxx:3000
Enter you name, email and password to create your account, this remains local information, nothing is going outside of the machine, I checked 😄
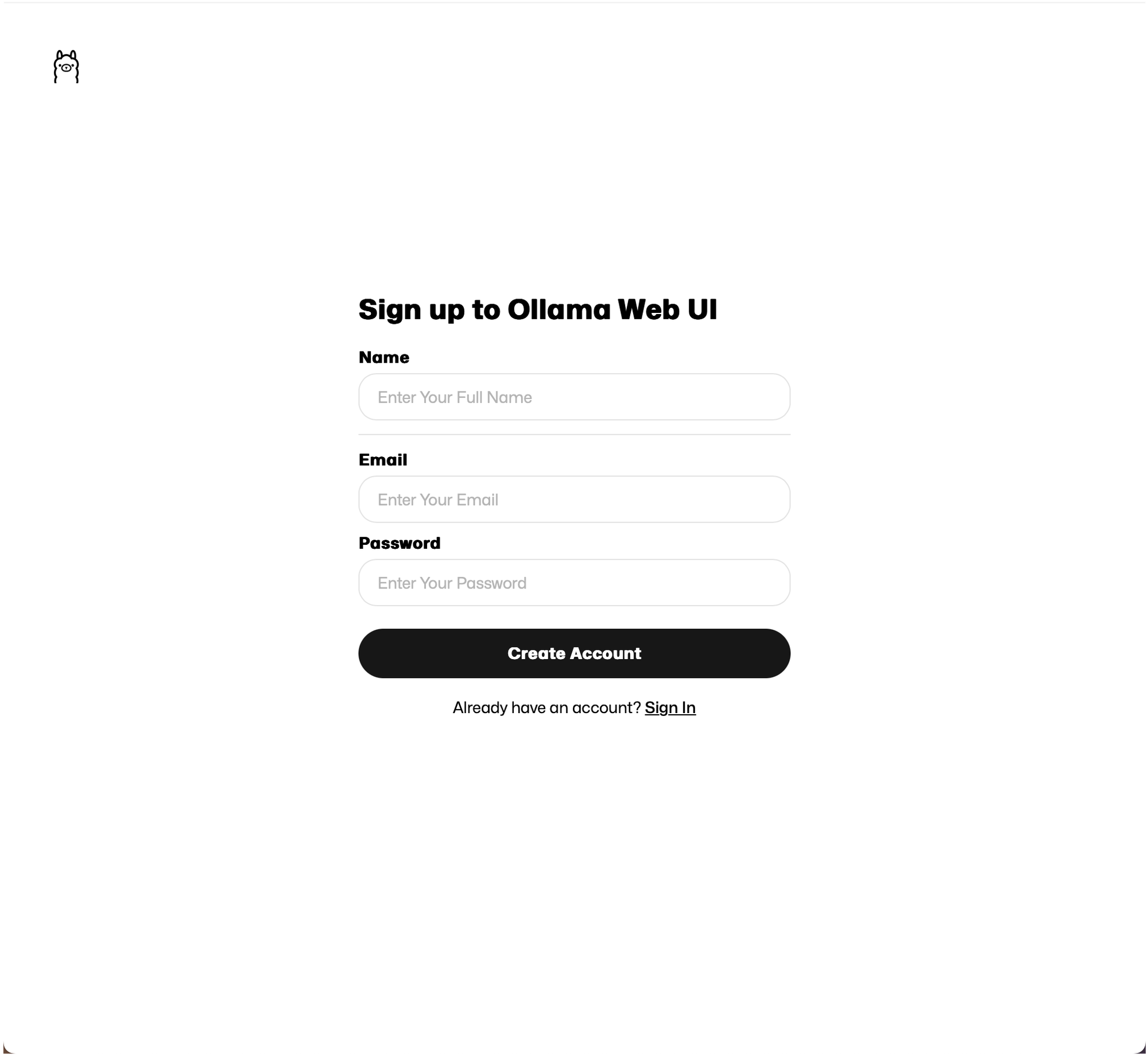
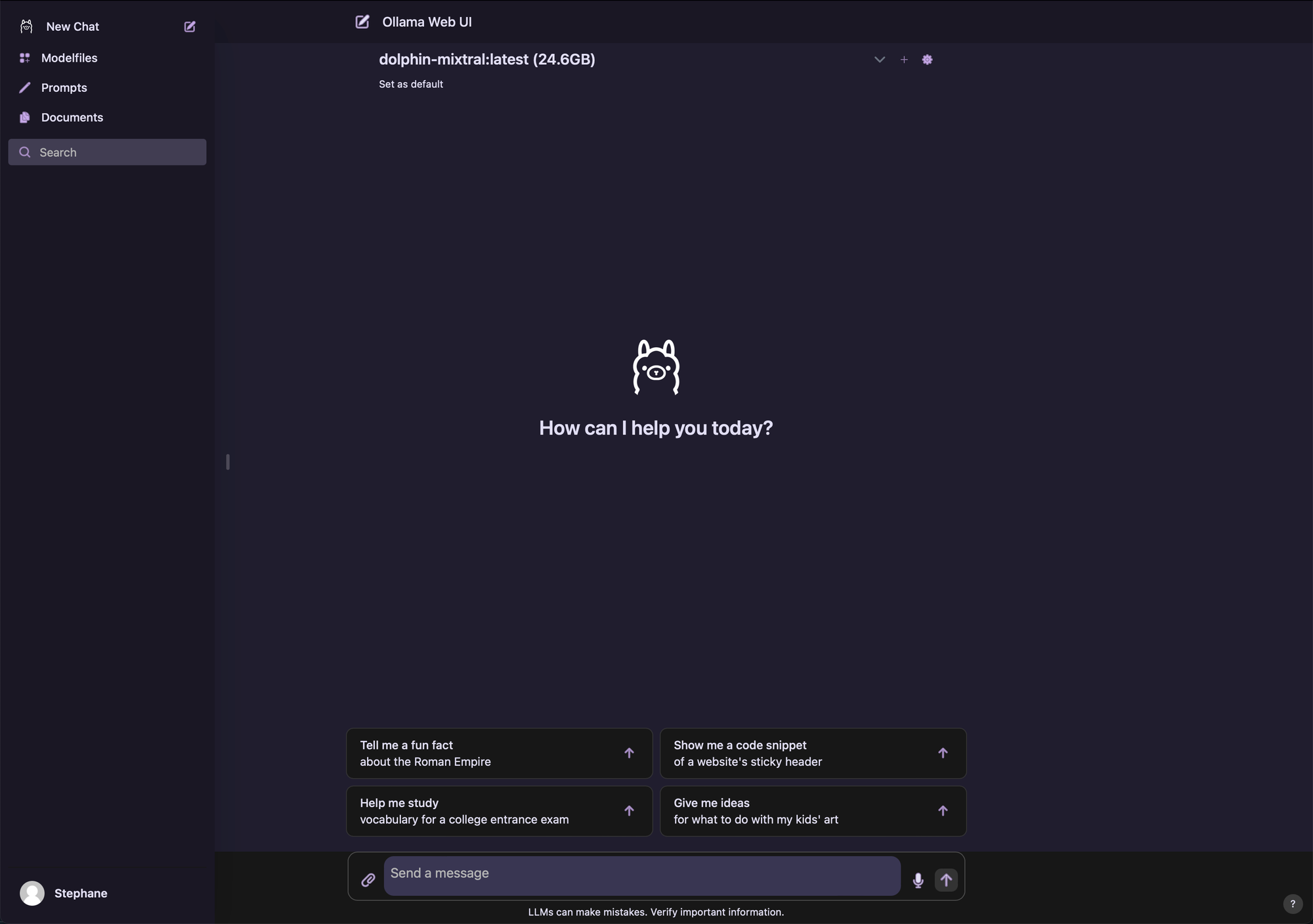
If you're familiar with ChatGPT you will quickly find your way in this UI
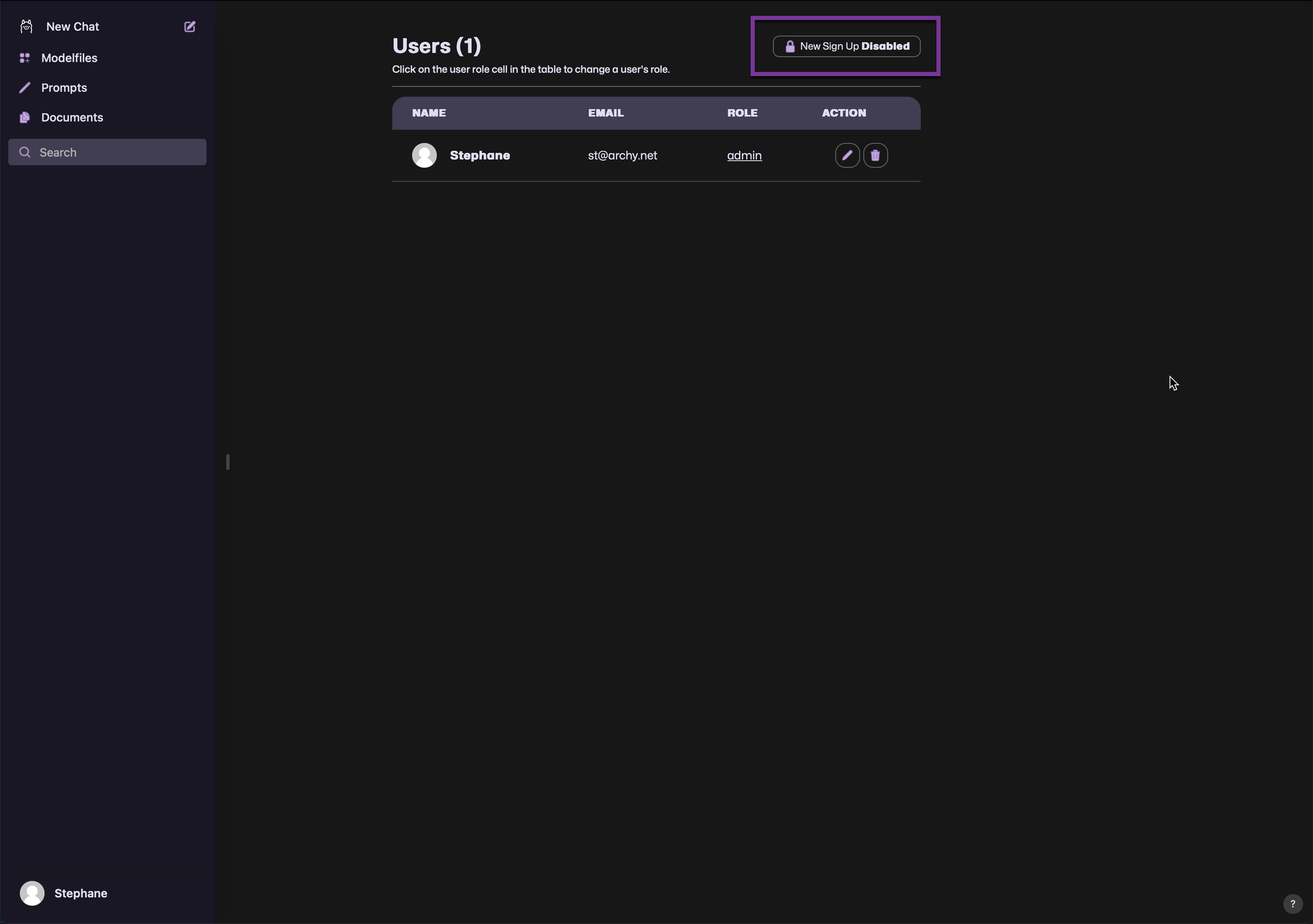
If you don't plan to have more user registering here, you should disable registration by click on the bottom left corner on your name to go to Admin Panel and click on the top on New Signup to disable new registrations
the if you go at the same place but chose settings, this is where we will chose the first model to use with Ollama
you can browse the link bellow to go to chose among all the available LLM
I chose Dolphin-mixtral which is a pretty popular model to play with. It can take some time to download, it depends of your internet speed.
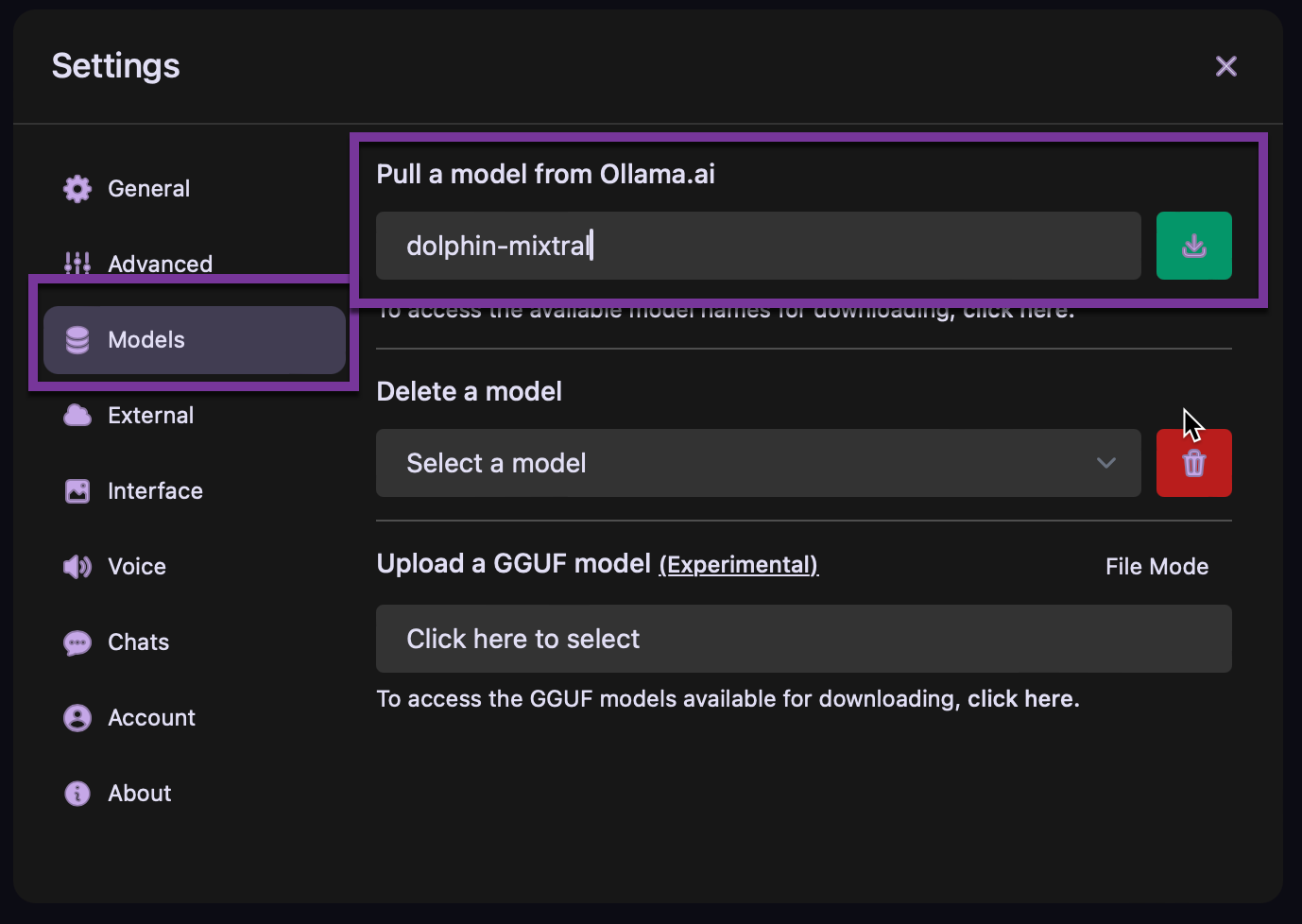
On this is downloaded, you can chose to make it a default model so it will load into GPU when you login to Ollama.
You can now interract with this model using Ollama Webui !