AI
Why My Mac Mini M4 Outperforms Dual RTX 3090s for LLM Inference
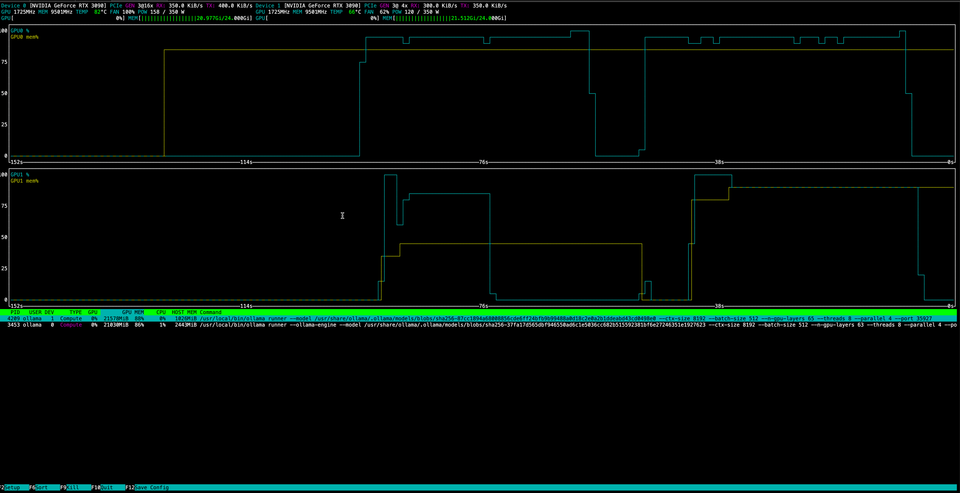
I built a dual RTX 3090 server for local LLM inference. A Mac Mini M4 turned out to be 27% faster and 22× more efficient. Here's why memory bandwidth beats raw GPU power.